
245のAI原則を調べて分かったこと
AI原則の策定にとどまらず、具体的な実践と継続的な改善のサイクルを確立することが、原則を「絵に描いた餅」にしないために必要な活動です。
AI原則ってなに?
AI原則とは、組織が人工知能技術を倫理的かつ責任を持って開発・展開・利用するための指針や枠組みを指します。例えば Google AI Principles のように、ビジョンに沿ったAI開発を進めるための約束であり、顧客に対する宣言でもあります。これらは、コンプライアンス違反や法的責任のリスクを軽減する目的で策定される一方で、不安を伴うAIに対するイメージを和らげるため、データプライバシーや倫理性を重視した開発を行うという意思表示の役割も果たしています。
生成AIの利用が広まったことで、AI原則を掲げる組織が増えてきましたが、伝え方には共通点があるのでしょうか。よく使われている単語は何でしょうか。今回、48社の245の原則を調査してみました。
多くの組織に見られる原則の共通点は以下の3点です。
- プライバシーとデータ保護:ほぼすべての組織が、ユーザーデータの保護とプライバシーの尊重を強調しています。BoxやIntuitのように、顧客データを学習に利用しないと明言している企業もあります。
- 透明性と説明責任:多くの企業が、AIシステムはユーザーに対して透明であり、説明可能であるべきだと強調しています。eBayは、AIのライフサイクルの段階に応じて、AIの使用に関する情報を開示すると述べています。
- 公平性と包摂性:公平で偏りのない、包摂的なAIシステムの構築に強い関心が寄せられています。Philipsは、データに多様性を持たせることで、バイアスや差別のない開発と検証を行っています。
実際、「プライバシー(Privacy)」「透明性(Transparency)」「公平性(Fairness)」は、原則をワードクラウド化しても大きく表示されました。

AI原則に共通点が見られる一方で、独自の表現を使っている組織もあります。例えば、OpenAIはターゲットユーザー(顧客)ではなく「人類(Humanity)」という大きなスケールで捉えた原則を掲げています。また、Moodleは「設定可能性(Configurable)」という言葉を用い、ユーザーがAIをどのように活用するかを自分でコントロールできることを強調しています。
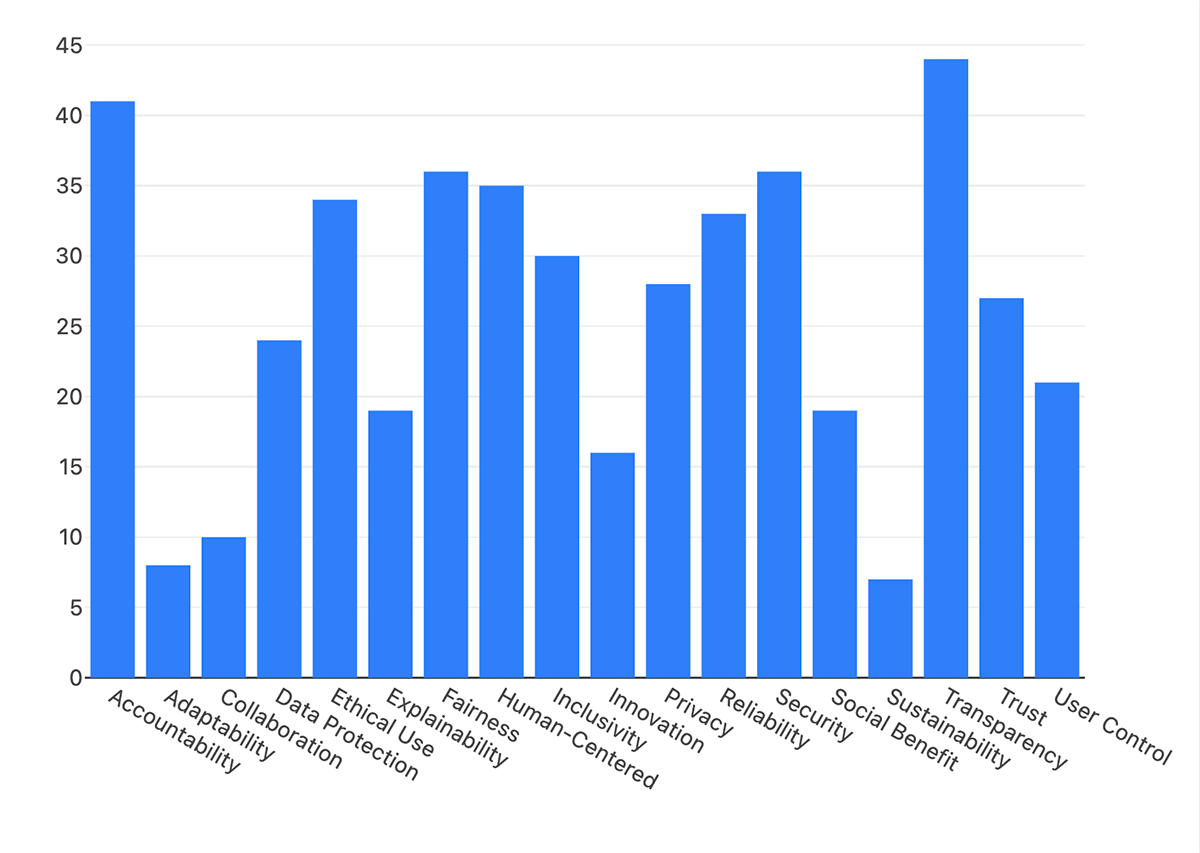
AIにあるブラックボックス問題への懸念から、透明性、公平性、説明責任といった倫理的配慮を示す原則が多く見られますが、各組織は自社の業界特性に合わせてアプローチを調整しており、同じ表現を使っているわけではありません。こうした配慮は、AIが社会に広く影響を与えることを認識し、多くの組織がAIを社会的利益のために使用することを表明していることの現れと言えます。
一方で、AI原則の具体性には組織間で差が見られます。ほとんどの組織は一般的なガイドラインを提供しているだけで、詳細な実施戦略を提示している組織はわずかです。また、倫理性や社会責任を強調する一方で、雇用への長期的影響や意思決定におけるAIの役割については、あまり触れられていないことも特徴的です。このように、あやふやな原則がどのように遵守され、正しい方向へ進んでいるかを測定・確保する方法が、現時点では十分に整備されていない現状が浮き彫りになっています。
語るのは簡単、実行は困難
「透明性」や「公平性」といった耳障りの良いフレーズを交えた原則を掲げる組織は多いですが、必ずしもその原則通りに行動しているとは限りません。例えば、「不公平な偏見を生み出したり強化したりしないこと」という原則を掲げているGoogleにおいても、自社の倫理的AIへの取り組みと実際の行動に矛盾があると指摘したAI倫理研究者のTimnit Gebru博士が退職に追い込まれたエピソードがあります。
Google hired Timnit Gebru to be an outspoken critic of unethical AI. Then she was fired for it.
Appleの「Apple Card」に使用されているAIシステムが、女性に対してバイアスを持っていることが2019年に判明しました。女性の方がクレジットスコアが高いにもかかわらず、男性よりも低いクレジット限度額が提示されるケースが多く報告されたのです。「細心の注意を払ってデザインする」という原則を掲げるAppleでも、時にはその原則が守られていないことがあります。
 By
By
コンプライアンス違反や法的責任のリスクを軽減するためとはいえ、原則を違反したからといって必ずしも罰せられるわけではありません。利益やマーケットシェアの拡大は、公平性や差別禁止といった倫理的な配慮と対立することがあります。その結果、企業はビジネス目標を倫理的ガイドラインより優先し、自ら掲げた原則と矛盾する行動を取ることがしばしば見受けられます。これはAIだけでなく、デザインにおいても同様です。ダークパターンを好ましく思う人はいないですが、それでも世に出てしまうのは、同じような事情が背景にあると言えるでしょう。
こうした原則と行動の差異が生まれる要因は、短期的な利益を追い求めるビジネスの問題にとどまりません。公平性や透明性といった概念を技術的な問題として捉え、アルゴリズムなどの技術的手段で解決できると考える点にも問題があります。「AIをどう開発すべきか」という視点に限定すると、AIを使用することで人権や心身の安全、環境などに及ぼす社会的影響の全体像を見落としがちです。また、欧米企業のAI原則が日本文化に合うとは限りません。「フリースピーチ」や「プライバシー」といった言葉に対する見解や期待にも違いが生じるはずです。
AI原則を掲げていても、具体的な対策が見えにくく、状況によって守られないことがあります。また、人によるチェックが曖昧になることも少なくありません。Claude を開発する Anthropic では、AI原則を作らずに「Constitutional AI (CA)」というアプローチを採用しています。CAIは、人間のフィードバックを減らし、定められた『憲法』に基づいてAIが自己批判と自己改善を行うことを重視しています。また、社会的な規範や価値観の進化に応じて倫理的ガイドラインを継続的に監視・更新できるため、より柔軟でスケールしやすいと言われています。
Microsoftは、Responsible AI Principles and Approach というページを設けていますが、他社のような原則は提示していません。その代わりに、Microsoft Responsible AI Standard(PDF)というチェックリストに近いドキュメントを公開しています。これは、原則に基づいてどのように考え、行動すれば良いか分からない点を解消するためのアプローチといえます。
AI原則は、技術の倫理的な開発と利用を導く重要な指針です。しかし、その実効性を高めるためには、具体性と測定可能性の向上や文化的多様性の考慮など、多面的なアプローチが必要です。透明性を強調するなら、AI原則の遵守状況を定期的に公開し、自社チェックだけでなく第三者機関による監査を受けるなど、透明性と説明責任を強化する仕組みづくりが求められます。原則の策定にとどまらず、具体的な実践と継続的な改善のサイクルを確立することが、原則を「絵に描いた餅」にしないために必要な活動です。

Yasuhisa Hasegawa
Web やアプリのデザインを専門しているデザイナー。現在は組織でより良いデザインができるようプロセスや仕組の改善に力を入れています。ブログやポッドキャストなどのコンテンツ配信や講師業もしています。