
1万文字のフィードバックを2秒以内で分析する方法
大量のユーザーフィードバックを放置したままにせず、効率的な分析方法から試してみてはいかがでしょうか。
統計モデルを使ってみよう
今年の初めに UXリサーチでAIが使えるか検証してみました。最近だと ChatGPT で Code Interpreter が利用できるようになったことで、アップロードしたデータを使って質問したり加工できるようになりました。AI 活用の幅は今も広がり続けていますが、当たり障りのない回答は少なくないですし、組織のポリシーで AI が利用できない場合もあります。 AI には AI のバイアスがありますし、それが生成する見解が必ずしも組織の立場と一致するとは限りません。
AI だけでなく、機械全般の強みは、大量のデータを素早く処理する能力です。 Google の Cloud Natural Languageを使用したテキスト分析は実践したことがありますが、AI や機械学習を頼らず手間を省いて分析する方法がないか調べてみました。
今回、LDA(Latent Dirichlet Allocation)を用いる手法を試してみました。これはテキストデータからトピックを抽出するための統計的モデルです。
例えば、ある記事がデザインに関する話題が30%、リサーチに関する話題が20%、そして組織に関する話題が50%で構成されているとします。LDAはこのような「トピックの混在」を検出し、各文書がどのトピックからどれほど影響を受けているかを推定します。
つまり、大量に寄せられるユーザーフィードバックから頻出するキーワードを抽出し、各キーワード間の関連性を明らかにすることで、フィードバックの傾向を推察することが可能になります。
収集されるユーザーフィードバックを手作業で分析するのは非常に時間がかかるだけでく、分析のバイアスが入ることがあります。LDAを利用することで、大量のフィードバックから自動的に主要な傾向を抽出することが可能になります。これにより、ユーザーの関心や問題点が何であるかを短時間で把握することができます。
今回は、Gensim:や Neologism などを利用して、簡単な分析ツールを作ってみました。スクリプトは Google Colab に公開してあるので、興味がある方は自分で試してみてください。


今回サンプルで使ったのはJPX上場会社ESG情報WEBの表題情報。表題数200件。6000文字の情報を、およそ1秒で処理。下記は出力されたデータです。
Topic 1: 0.033*"レポート" + 0.021*"導入" + 0.021*"自然" + 0.021*"設備" + 0.021*"冷媒" + 0.021*"AI" + 0.016*"における" + 0.016*"技術" + 0.012*"いたし" + 0.011*"お知らせ"
Topic 2: 0.026*"について" + 0.015*"ESG" + 0.013*"用い" + 0.013*"シート" + 0.013*"FTSE" + 0.013*"産業廃棄物" + 0.013*"取得" + 0.013*"許可" + 0.013*"PTP" + 0.013*"破砕"
Topic 3: 0.016*"人材" + 0.016*"製造" + 0.016*"マネジメント" + 0.016*"共同" + 0.016*"推進" + 0.016*"バイオ" + 0.016*"サプライヤー" + 0.016*"供給" + 0.016*"半導体" + 0.016*"育成"
Topic 4: 0.075*"統合" + 0.069*"報告書" + 0.019*"炭素" + 0.017*"レポート" + 0.013*"実行" + 0.013*"開催" + 0.013*"日本企業" + 0.013*"ファンド" + 0.013*"住友林業" + 0.013*"グループ"
Topic 5: 0.045*"について" + 0.026*"私募債" + 0.026*"寄付" + 0.026*"みや" + 0.026*"贈呈" + 0.026*"伴う" + 0.026*"ぎん" + 0.026*"引き受け" + 0.019*"支援" + 0.019*"SDGs"
Topic 6: 0.081*"に関する" + 0.076*"報告書" + 0.051*"サステナビリティ" + 0.051*"レポート" + 0.024*"更新" + 0.013*"カーボンニュートラル" + 0.013*"GAZOO" + 0.007*"実現" + 0.007*"未来" + 0.007*"株式会社"
Topic 7: 0.131*"レポート" + 0.047*"TCFD" + 0.045*"サステナビリティ" + 0.015*"お知らせ" + 0.013*"データブック" + 0.010*"CSR" + 0.010*"人権" + 0.010*"続け" + 0.010*"推進" + 0.010*"実現"
Topic 8: 0.028*"データ" + 0.028*"SDGs" + 0.022*"策定" + 0.022*"宣言" + 0.022*"支援" + 0.022*"について" + 0.021*"ESG" + 0.017*"環境" + 0.012*"向け" + 0.012*"構築"
Topic 9: 0.045*"DX" + 0.023*"FACTBOOK" + 0.023*"実績" + 0.023*"未来へ" + 0.023*"KEIAI" + 0.023*"羅針盤" + 0.016*"向け" + 0.016*"プレスリリース" + 0.016*"中小企業" + 0.016*"インタビュー"
出力されたデータを基に pyLDAvis というライブラリを利用して視覚化してみました。どの単語がどのトピックで頻繁に使用されているかを容易に確認できるようになり、全体の傾向との比較も簡単に行えるようになりました。「△△は〇〇である」という明確なテーマはなく、あくまでも単語からの推測に過ぎませんが、新たな視点を提供し、さまざまな思考のきっかけになります。
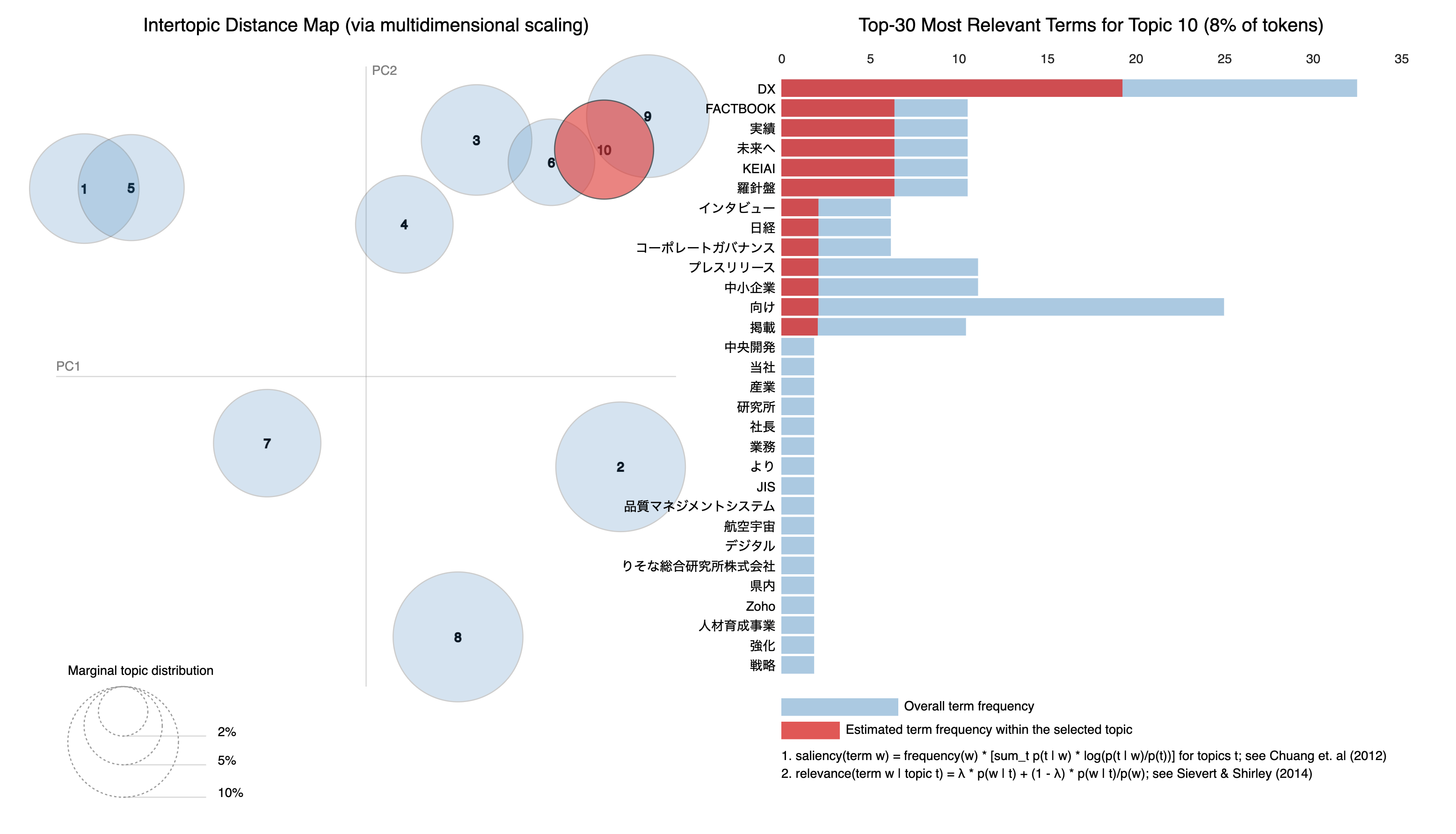
分析を始めるためのキッカケに
試しに案件で収集した15万文字含まれている 1,300のフィードバックを分析してみましたが、およそ 20 秒で処理し、10つのグループに分類できました。これくらいの情報量を数年前に手作業で分類したことがありますが、当時とは比べ物にならないくらいのスピードです。傾向をみるための手段のひとつにすぎないので、これだけで正確なユーザー課題を導き出せませんが、手作業ではできないスピードで傾向把握ができます。
大量のユーザーフィードバックを収集しても、活用できずにどこかで眠ってしまうことはよくあります。長期間同じプロダクトに携わるデザイナーでも、フィードバックに触れないことで、気づかぬうちにユーザーに対する感覚が鈍ってしまいます。LDAの利用は、リサーチャーの分析を不要にするわけではありませんし、プロダクトの問題点が明らかになるほど簡単な話ではありません。さらに、分析方法は他にもいくつか存在します。しかし、何もせずに放置するよりも、今回のような手法を使って何か新しい試みを始めることも一つの選択肢だと思います。

Yasuhisa Hasegawa
Web やアプリのデザインを専門しているデザイナー。現在は組織でより良いデザインができるようプロセスや仕組の改善に力を入れています。ブログやポッドキャストなどのコンテンツ配信や講師業もしています。