
生成UIで変わるのはデザイン作業効率化だけではない
UI生成の発展により、UIデザイナーの働き方やデザインプロセスにも変化をもたらします。ツールを活用するために、デザイナーの役割に変化が幾つか考えられます。
AppleとGoogleが見据える生成UIの世界
AIを活用した今後のUIデザインを考察する上で、プラットフォームを開発するAppleとGoogleの動向は注目です。両社ともマルチモーダル大規模言語モデル(Multimodal Large Language Model / MLLM)の研究を進めており、その成果が公開されています。
Apple が開発している Ferret-UI は、モバイルアプリのUIを自動的に分析し、アクセシビリティや使いやすさの観点から改善案を提示するAIモデルです。色のコントラストの不足やタップ領域の狭小化などを指摘し、ガイドラインに沿った修正案を示唆します。デザイナーはこのフィードバックを基に、より洗練されたUI設計が期待できます。
一方、Google が開発している ScreenAIは複雑なインタラクションも含めたUIの理解が可能で、操作ガイドやテストなど利用ケースが考えられます。また、UIだけでなく、画像やインフォグラフィックのような文字以外のコンテンツも理解ができます。
実用化は少し先かもしれませんが、Ferret-UIやScreenAIのようなモデルを使えば、デザイナーはアクセシビリティ、ユーザビリティ、一貫性の問題についてUIデザインの自動監査ができるようになります。デザインガイドライン、ベストプラクティス、自社データに基づいた改善提案との組み合わせると、さらに効果が増すはずです。今は生成UIには、プロンプト入力が欠かせないですが、レイアウトの最適化、色のコントラストの調整、デザイナーの入力に基づいた代替デザインのバリエーションの生成などリアルタイムのフィードバックやデザインバリエーションの生成なども期待できます。
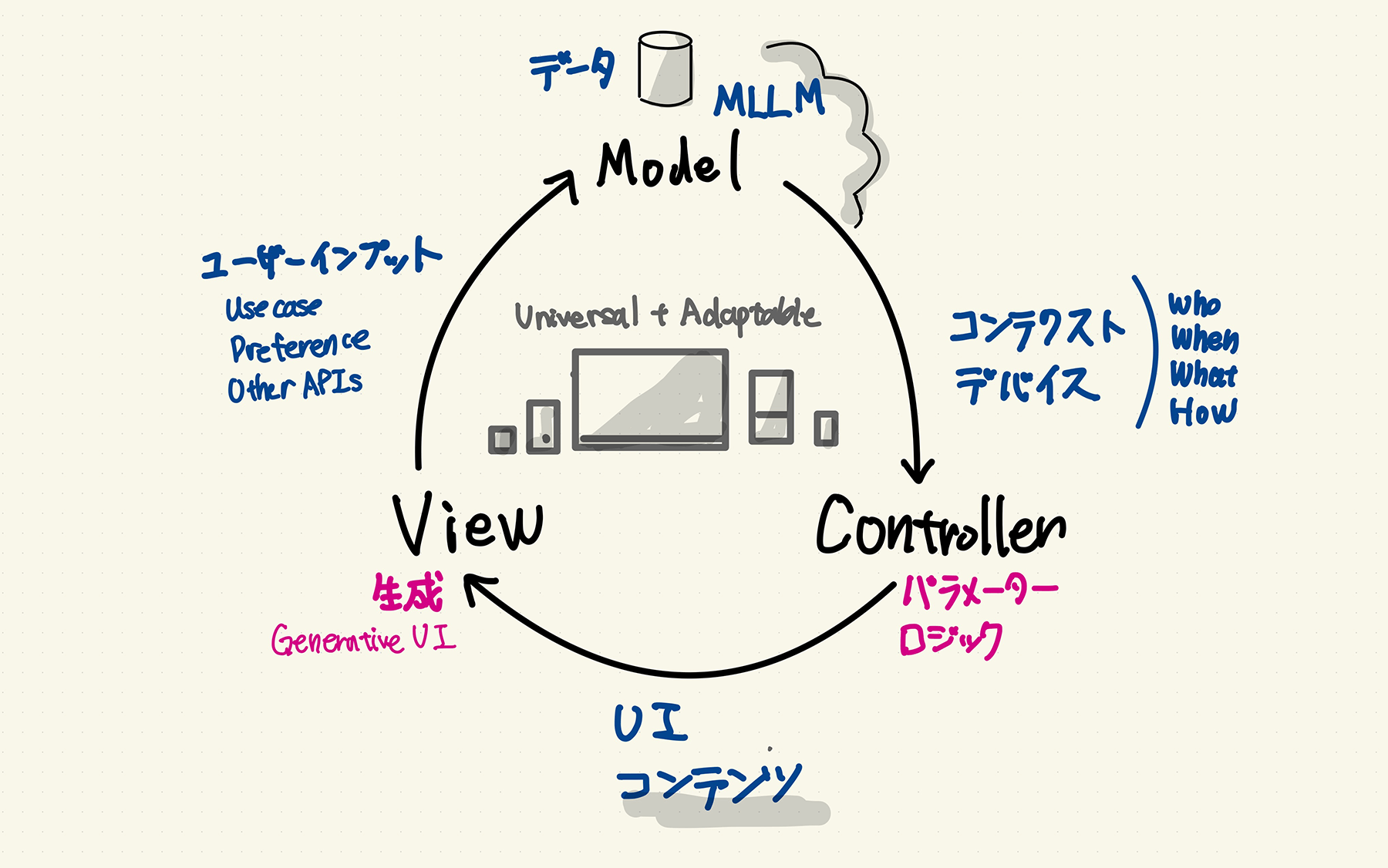
ダイナミックな生成UIの可能性と働き方の変化
AIが自動的にUIをデザイン・生成する「ジェネレーティブUI」は、今既に幾つかのサービスで提供されています。(WebサイトのAI生成も含めるともっとありますが、今回はUIデザインのみ)
多くのサービスは、プロンプトを入力して画面を生成するといったシンプルなものですが、Ferret-UIやScreenAIのようなモデルが活用できるようになると、ユーザーのニーズや行動データをなど大規模なデータセットを分析し、デザインパターン、ユーザーの好み、パフォーマンスに合わせたUI生成も考えられます。これまでは平均的なUIの提案しかできませんでしたが、ユーザーの文脈を理解したパーソナライズ(ダイナミックなUI生成)も夢ではなくなりつつあります。
アプリ内のUIには、静的に保持したい部分と動的に変更したい部分が混在する場合があります。そこで、UIコンポーネントにパラメーターのようなものを設定し、AIがユーザーに代わって変更できる箇所や、ユーザーが設定を上書きできる箇所を宣言する未来も考えられます。ただし、ユーザーごとに大きく異なるUIは学習負荷になるため、ユーザーの特徴や文脈に合わせた適切な変更に留めるべきでしょう。
人それぞれ異なる UI を提供するのは、ユーザーに学習負荷がかかるので良くないという見解があります。大幅に見た目を変えることがダイナミックなUI生成の本質ではありません。無闇に見た目を変えるのではなく、ユーザーの特徴や文脈に合わせたパーソナライズはメリットになるはずです。色覚障害がある方にとって見難いUIの色を調整したり、脳や神経を刺激しすぎないような情報量に変えることもできるでしょう。今でも iPhone の集中モードでOSレベルで様々な設定ができますが、生成UIの発展により、アプリ側でも新たな配慮が可能になるかもしれません。
生成UIの技術がデザインワークフローの一部になることは、単なる新手段の追加ではありません。例えば、 Firefly でグラフィックを作るワークフローは、Photoshop や Illustrator で作るときとは異なる発想を要します。テキスト、参照画像、パラメーターを変えながら徐々に精度を上げていくプロセスは、作り方だけでなく考え方の変化も必要です。おそらく、生成UIを活用したデザインは、ピクセルやベクターを使った見た目の調整するという考え方の脱却も必要かもしれません。
UIデザイナーは下記のようなことを考え、生成UIと協働しながら画面設計をする役割に変化するでしょう。ユーザーのニーズをデータとして表現し、機械学習モデルに入力できる形式に『翻訳』することが求められます。ユーザーの行動やフィードバックをデータとして収集・分析し、AIシステムが処理できる形式に変換するプロセスを確立する必要があります。
- パラメータと制約の確立:生成UIが守るべきデザイン原則と制約を確立します。一貫性を保つべき点、ダイナミックにする範囲、重視するユーザビリティなどを定義し、適切なUIが生成されるようコントロールします。
- 明確なユーザーアウトカムの定義:ユーザーの目標と望ましい結果(アウトカム)に沿ったUIを生成するための基準を伝える共通言語とフレームワークを提供します。
- リサーチインサイトからの判断と模索:リサーチインサイトを生成UIを支えるAIシステムに提供します。個々のユーザーのニーズに合わせて、生成UIがどのようなデザインを提供すべきかを模索していきます。
- より洗練したデザインシステムの構築:コンポーネントの使用状況やパフォーマンスを基に、ベストプラクティスを学習します。必要に応じてコンポーネントの改善や適切な組み合わせ方を設計していきます。
- 倫理的で包括的なデザイン実践:AIが生成したデザインが特定の属性を持つ人を排除していないか、常にチェックする必要があります。潜在的なバイアスや意図しない結果を特定し、判断を下せる能力が求められるでしょう。
新たな役割と責任
Ferret-UIやScreenAIに代表される、UIの理解と生成に特化したAIモデルの登場は、UIデザインの未来を大きく変える可能性を秘めています。アクセシビリティの向上、UIテストとデバッグの効率化、デザイン支援、対話型UIデザインプロセス、パーソナライズされた適応型インターフェースなど、様々な可能性が広がっています。
しかし、だからこそ人間のクリエイティビティや倫理的価値観がこれまで以上に問われるようになるでしょう。AIという新しいパートナーを使いこなし、より良いデザインを提供するためには、エンジニアやAI/機械学習の専門家とのコミュニケーションも欠かせません。AIの力を活用しながらユーザーへ真の価値を提供するデザインを追求していくことが、これからのUIデザイナーに求められる資質になるでしょう。
補足:生成UIについて、下記の記事も参考になります。
 Kate Moran
Kate Moran
生成AIとクリエイティビティを題材にポッドキャストもしました。


Yasuhisa Hasegawa
Web やアプリのデザインを専門しているデザイナー。現在は組織でより良いデザインができるようプロセスや仕組の改善に力を入れています。ブログやポッドキャストなどのコンテンツ配信や講師業もしています。